La tecnología es mojo, el marketing despojo
La tecnología es mojo, el marketing despojo🔗
La tecnología es mojo🔗
Partiendo de que para mí un arado es tecnología, me cuesta entender a los primitivistas. Son gente que pone barreras arbitrarias separando la evolución tecnológica de milenios en "esto está bien, esto está mal". Muchas veces sin defenderlo con criterios éticos, lógicos, consistentes, que te llevarían a un depende.
Tampoco soy un flipado de la tecnología que piensa que podemos maltratar el medio ambiente de todos, para que cuatro se enriquezcan, porque el día de mañana habrá una revolución científico-tecnológica que lo arreglará todo. Y es más de flipado todavía cuando quien te argumenta eso dedica su día a día en recortes en investigación y una educación más sectaria centrada en seres superpoderosos imaginarios. Y no me refiero a los seres imaginarios de la franquicia Marvel.
La tecnología es algo con una cara fea, otra bonita, pero siempre un reto intelectual con el que se aprenden cosas. A la gente que le dió por construir arados por primera vez debían estar cansados de remover la tierra con un palo o vete tú a saber cómo. Pero ese decantarse por remover la tierra tuvo que ser fruto de la observación y aprendizaje de la agricultura. La tecnología tiene una belleza en sí misma, una lucha entre esfuerzo y tesón para conseguir algo más simple y cómodo. Una lucha constante contra la monotonía, intentando nuevos puntos de mejora. A veces pequeños avances, otras veces cambios completos de paradigmas.
El marketing es despojo🔗
Para mí el marketing es ilusionismo en el mejor de los casos. En el mejor de los casos ocultan los puntos flacos, centrándose solo en los puntos fuertes para atraer a una mayor cuota de mercado. Y tras esas cuotas de mercado hay personas que se decepcionaran al descubrir esas carencias. En el peor de los casos, muy habitual por otra parte, es directamente engaño:
- Se miente exagerando bondades que no son reales.
- Se miente ocultando defectos conocidos.
- Se miente vendiendo unas futuras mejoras que no se sabe si son posibles.
- Se miente sobre productos que comparten el mismo nicho para hacerlo menos atractivo.
- Se miente. Y mucho.
El marketing es una lacra que parasita los recursos de las personas a quien va dirigido. El marketing es involución. El marketing es despojo.
Cuando se mezcla marketing y tecnología🔗
Los ingenieros no son seres de luz, tienen necesidades y en un mundo capitalista hace falta atraer inversores para poder cubrir esas necesidades mientras se desarrollan nuevas tecnologías o se evolucionan las actuales. Y a veces se pacta con el diablo del marketing para conseguir ese objetivo. Muchas veces con la buena intención de dejar de engañar cuando se consigan las mejoras prometidas gracias a esos recursos. Pero pactar con el marketing tiene un lado oscuro y muy peligroso en forma de funcionalidades no funcionales para alimentar el marketing, priorización de objetivos por parte del inversor, desconfianza de los usuarios de la tecnología, competencia desleal a ingenieros íntegros que no venden humo,...
Hay muchos ejemplos de esta mezcla de tecnología y marketing, pero me centraré en las relacionadas con el desarrollo de software:
- Se sacan un montón de funcionalidades no funcionales que no están production ready para rellenar una comparativa de funcionalidades con la competencia. Un check solo implica que esa funcionalidad existe, pero en ocasiones no es usable y si no eres precavido te enteras cuando te has casado con esa tecnología.
- Se suele con parafrasear a Mark Twain con la frase lies, dammed lies, statistics,... and benchmarks por la de veces que se usa un mal benchmark para vender algo que no es real. Los benchmarks, incluso cuando tratan de ser objetivos siguen siendo peligrosos porque suelen caer en la ley de goodharts (cuando una métrica se convierte en objetivo deja de ser una buena métrica). Un benchmark que no te advierte de que no es fiable, no es para nada fiable.
- Se venden funcionalidades no desarrolladas imposibles de implementar en los plazos fijados. En demasiadas empresas "tecnológicas" las estimaciones de los ingenieros se tienen que ajustar a las mentiras de marketing que se le han contado al cliente.
- Los propios ingenieros, para escapar de sus empresas
tecnológicasde marketing se dedican a hacer networking, que en muchos casos no es más que marketing de su propia persona. O meten con calzador tecnologías que no aplican en la solución del objetivo para poder engordar curriculum de cara a un cambio de empresa. - Se hace imposible encontrar información veraz sobre una tecnología de moda y los ingenieros tienen que dedicar bastante tiempo en cribar basura de marketing cuando busca información tecnológica.
- ...
Las partes positivas🔗
El retorno tecnológico tras la caída del marketing🔗
Recuerdo leer en un foro sobre NoSQL, en plena moda sobre ese tema, a un DBA explicando el por qué estaba aprendiendo esas tecnologías. Contrario a lo que pudiera parecer no se había dejado hipnotizar por los cantos de sirena marketinianos de un storage ultrarápido, ultra-escalable que dejaban obsoletas las viejas bases de datos relacionales abocadas a desaparecer. Él había hecho la siguiente apuesta: "Las bases de datos relacionales llevan evolucionando y mejorando durante más de 30 años y mucha gente que alocadamente se deja convencer por el marketing vacío de las NOSQL va a necesitar hacer una migración al antiguo sistema SQL cuando se den cuenta de su error".
Y con eso no quería decir que las NoSQL fueran una basura sin utilidad. Sino que mucha gente no había tenido en cuenta las bondades ACID que las bases de datos relacionales les brindaba y que echarían en falta al migrar a una NoSQL que las sacrificaba para obtener mejores resultados en benchmarks.
Esa loca gente del pasado, fanáticos de la atomicidad. ¿Para qué tantos pasos para ejecutar las operaciones? Entre sincronizaciones y copias de datos (mejor saltarse escribir en el Redo Log) la performance se iba al garete. Se recorta un poquito por aquí, se consigue más velocidad y todos contentos. Hasta que un cliente se daba cuenta de la cantidad de esfuerzo que tenía que hacer con las nuevas tecnologías para no acabar teniendo pedidos a medias en su flamante base de datos NoSQL.
¿Consistencia? ¿No te vale eventual? Porque ya conocemos el teorema CAP y si quieres asegurar la consistencia de estos sistemas distribuidos super-escalables hay que sacrificar la alta disponibilidad o la tolerancia a particionados. La ausencia de atomicidad tampoco te iba a permitir consistencia, así que qué más da. El pastizal de horas hombre nivelando datos y los costes de las incidencias de clientes enfadados te los vas a comer igual.
Isolation, aislamiento, no es esto demasiado académico para el pragmatismo de las nuevas tecnologías NoSQL. Pues lo es hasta que tienes lecturas fantasma, eso si muy rápidas, y estropeas un poquito más la consistencia. ¿Pero qué lecturas fantasma si no hay datos en el limbo de las transacciones que proporcionan atomicidad? Pues de las cosas medio escritas a disco o de... Bueno, a lo mejor se puede meter algún lock aunque baje algo el rendimiento.
Durabilidad. Tampoco es necesario hacer un fsync a disco para garantizar que los datos quedan escritos. Con que los tenga otro nodo del cluster el dato ya perdura. Y si no tienes cluster puedes activar la opción de fsync a disco. Eso si, todas estas opciones por defecto inactivas que estropean los benchmarks. Si luego alguien no lee la letra pequeña de nuestra campaña de marketing, culpa suya.
Y si, se produjeron cambios. El movimiento NoSQL (No SQL) paso a llamarse NOSQL (Not Only SQL). Que es lo que se hacía en los tiempos del SQL con el uso de LDAP o las Round Robin Databases. Y es cierto que había muchos proyectos que abusaban del SQL como tecnología única para el storage que ahora contaban con opciones mejor adaptadas a sus problemas específicos. También muchas NoSQL evolucionaron tecnológicamente tras el pinchazo del marketing y adoptaron muchas tecnologías más que probadas en diferentes BBDD SQL como el Multi Version Concurrency control, sistemas de storage más durables,... Supongo que sin todo ese humo ahora no tendríamos tantas time serie databases, vector databases, columnar databases, document databases,... y por supuesto bases de datos relacionales para elegir.
Lo didáctico del contra-ejemplo🔗
Lo mismo que hay patrones de diseño que te enseñan a cómo hacer las cosas, existen los anti-patrones de diseño que te advierten de errores que debes evitar cometer.
Recuerdo con especial cariño un hilo en una lista de correo sobre bases de datos. Imaginad el tiempo que hace que se usaban listas de correo y que trataba de por qué mysql se vendía a sí misma como la base de datos relacional más rápida de todas. Me resultaba ridículo que una de las pocas bases de datos relacionales sin integridad referencial se postulase como la más mejor de todas. Pero tras leer a expertos en diferentes motores SQL aprendí mucho y sonaba aún más ridículo.
Aprendí sobre la importancia de la reproducibilidad de un benchmark cuando mucha gente exigía ver qué parámetros de configuración habían usado para obtener unos resultados tan diferentes de sus propios benchmarks. Al hacerse públicos quedaban claros varios errores metodológicos, por ejemplo el utilizar los valores por defecto para PostgreSQL. PostgreSQL venía con unos parámetros optimizados para consumir pocos recursos al instalarse en una máquina de desarrollo, porque entendían que eran la mayoría de los casos y que la gente que despliega en producción sabe ajustar las configs.
Aprendí un montón sobre un montón de parámetros de configuración y funcionamiento interno de diferentes bases de datos a través de los mensajes de la gente que criticaba ese burdo benchmark. Diferentes estrategias para generar el plan de ejecución de las consultas, estructuras de datos sin bloqueos (o menos bloqueantes),...
Aprendí un montón sobre el standard SQL, el grado de compatibilidad de diferentes dialectos y lo que podía implicar en cuanto a rendimiento una alternativa a alguna de esas funcionalidades en un motor de BBDD más limitado.
También aprendí que el marketing, aunque sea burdo y esté desmontado, funciona. Me llegó un montón de veces a través de colegas ese benchmark explicándome por qué estaba equivocado al usar postgresql y por qué debería usar mysql. Y no niego que mysql es mi opción preferida para algunos escenarios, pero desde entonces siempre me pareció la opción tecnológica no fiable que debería ser probada y comparada con otras soluciones antes de ser utilizada en producción.
Las partes negativas🔗
La sensación constante de tiempo perdido🔗
No se puede luchar contra el marketing sin sufrimiento. Cada vez me parece más acertada la opción del tipo ese que aprendía NoSQL para forrarse haciendo migraciones a SQL de las víctimas del marketing. Supongo que se dió cuenta de que explicar que es eso de ACID, el MVCC,... a gente hipnotizada por los cantos de sirena del marketing es una lucha quijotesca. "Me quieres convencer de seguir usando tecnologías obsoletas porque eres un carcamal incapaz de adaptarse al cambio" seguro que fué algo que oyó mil veces antes de decidirse a aprender NoSQL en su apuesta por SQL.
He perdido mucho tiempo que nadie me devolverá discutiendo con supuestos ingenieros sobre tecnología. Es como preguntarle al teleoperador que trata de venderte la fibra si es simétrica, hay opción de ip fija o cualquier detalle técnico que pudiera parecerte relevante. No vas a sacar nada en claro.
Contando las estrellas🔗
Si tumbarse en una noche clara a contar estrellas te parece una perdida de tiempo es porque todavía no has tenido que valorar una librería/proyecto/tecnología importante, que vas a sufrir mientras dures en el empleo, con alguien que se limita a contar estrellitas en github. En una de las ocasiones tenía que evaluar dagster y no recuerdo que otras alternativas. A mí me interesaba evaluar si se cubrían nuestros requisitos, grado de madurez, bus factor del proyecto, tiempo de resolución de incidencias, opciones de mantener el proyecto pagando o por cuenta propia, trazabilidad, eficiencia,... a el solo parecía importarle contar putas estrellitas.
Yo: ¿Qué te parece si hacemos un par de pruebas de concepto antes de decidirnos una opción? Tanto tu propuesta, como la del chico nuevo parecen prometedoras, así estamos seguros de elegir algo de lo que no nos arrepentimos en el futuro.
Él: bla, bla, bla, este tiene estas estrellas en github y este otro tiene más, bla, bla, bla, estrellas, bla, bla, artículo de medium.
A un amigo, con el que se puede hablar sobre tecnología, le pase este enlace de dagster sobre el black market de estrellas de github. No le encontraba el sentido a que alguien pagase por estrellas de github. Le conté que había mucha gente que basaba mayormente su criterio en eso y no podría creerme, "¿qué ingeniero basa su decisión solo en eso?". Ninguno, pienso ahora.
Tener que justificar mis decisiones tecnológicas...🔗
... cuando soberanas gilipolleces pasaban como la cosa más normal del mundo.
Hacer las cosas como las hace google, aunque tú no seas google y solo consigas hacer cultos del cargamento está bien valorado. Usar aproximaciones más sencillas, fáciles de mantener y que cubren de sobra tus necesidades es raro.
- ¿Te crees mejor que Google? No, tampoco considero que soy google y mis requisitos no son los mismos.
- ¿Por qué usas postgresql en vez de mysql que es...
- ... el standard de bases de datos open source? El standard actual de BBDD es el SQL99 y el soporte más fiel es el de postgresql.
- ... la base de datos open source más usada? Y el sistema operativo más utilizado es windows, pero ninguno de los dos cubren mis necesidades.
- ... más rápido? Es más rápido en algunas situaciones, en otra es mucho más lento. Por ejemplo con query complejas.
- ... lo que usan las grandes? Si tuviera un ratio constante de updates, que cancelara la parte bloqueante del autovacuum y me obligase a hacer paradas de sistema para evitar el workaround problem probablemente también usaría mysql, pero ese no es mi caso y postgres me ofrece ventajas que si son mi caso.
- ¿Lo de mostrarte escéptico con las tecnologías mainstream es para venderte con unos aires de outsider? ¯_(ツ)_/¯
- ¿No sé por qué te niegas a migrar celery a rq que es lo que usa ahora todo el mundo y es más fácil? Porque desconfío fuertemente de las garantías de entrega de los mensajes de una cola basada en redis.
- ...
Por suerte me estoy haciendo mayor y puedo poner la excusa de "déjame tranquilo que ya estoy mayor para esas moderneces".
El estado de alerta🔗
Cada vez que un compañero de trabajo dice: he leído en un blog que..., fulanito que es muy influencer dice que..., he pensado que podríamos aprovechar el tirón de la tecnología..., por qué no migramos el proyecto a una arquitectura... Siempre, siempre, se me estremece alguna zona del cuerpo. Y eso es porque siempre suele terminar en plantear una decisión arriesgada sin ningún tipo de criterio tecnológico que los respalde. Solo criterios vagos como mola, es guay, es lo que se usa ahora, ... Y pasa más cuanto más joven y apasionado es el desarrollador que hace el comentario. Creo que esa chavalada debería hacer guardias para ver si se le pasaba toda esa gilipollez.
Con gente que se limita a hacer sus ocho horas de forma totalmente desapasionada me siento mucho más tranquilo. Y en cierta manera eso me inquieta.
Analizando si es mojo o despojo🔗
Pongamos el ejemplo de una tecnología concreta para ver si es mojo.
Una página con un diseño currado (no el típico html cutre de developer quemado como este blog). Un tema interesante: algo que te permite reutilizar el ecosistema python, pero al mismo tiempo lograr todo tipo de optimizaciones de bajo nivel. Me pone.
Pero luego se marcan esto:
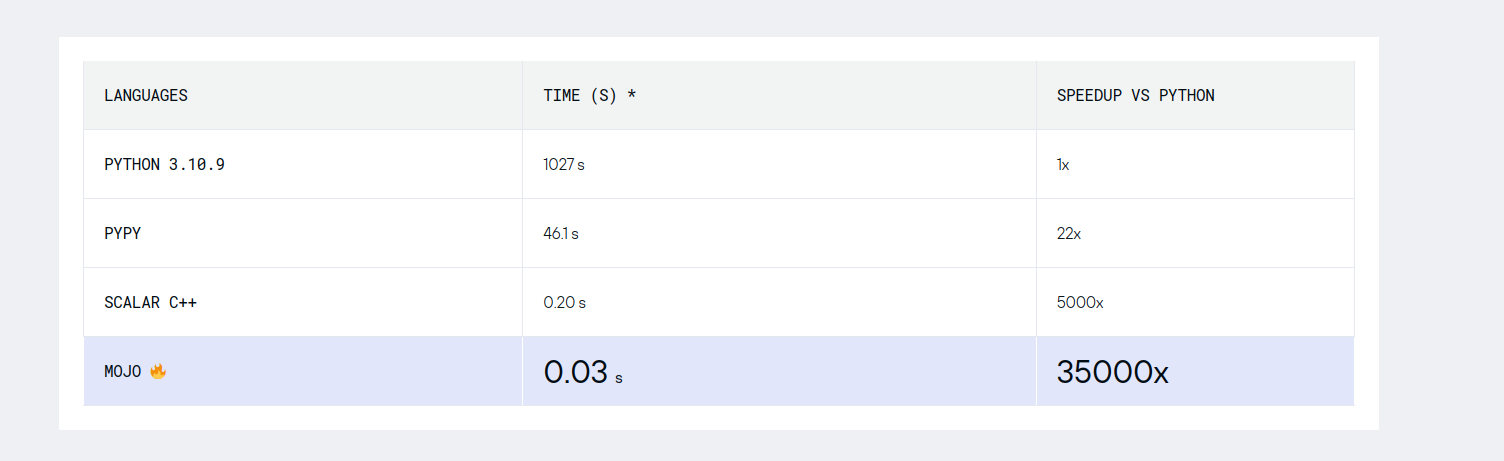
Ojo cuidado, es 35.000 veces más rápido que python y 7.000 veces más rápido que C++. Suena a la típica broma de los anglosajones del 1 de abril, su día de los inocentes.
Hojeando la docu🔗
Mirando un poco por encima me encuentro otro benchmark. A ver cómo explican ese 35.000 veces más rápido que python y 7.000 veces más rápido que C++.
El ejemplo inicial en python🔗
La función sobre la que se hace el benchmark
def matmul_python(C, A, B):
for m in range(C.rows):
for n in range(C.cols):
for k in range(A.cols):
C[m, n] += A[m, k] * B[k, n]
Y el código para ejecutar el benchmark
import numpy as np
from timeit import timeit
class Matrix:
def __init__(self, value, rows, cols):
self.value = value
self.rows = rows
self.cols = cols
def __getitem__(self, idxs):
return self.value[idxs[0]][idxs[1]]
def __setitem__(self, idxs, value):
self.value[idxs[0]][idxs[1]] = value
def benchmark_matmul_python(M, N, K):
A = Matrix(list(np.random.rand(M, K)), M, K)
B = Matrix(list(np.random.rand(K, N)), K, N)
C = Matrix(list(np.zeros((M, N))), M, N)
secs = timeit(lambda: matmul_python(C, A, B), number=2)/2
gflops = ((2*M*N*K)/secs) / 1e9
print(gflops, "GFLOP/s")
return gflops
python_gflops = benchmark_matmul_python(128, 128, 128).to_f64()
# 0.005480328057626661 GFLOP/s
Si haces la prueba de ejecutarlo verás un error en la línea:
python_gflops = benchmark_matmul_python(128, 128, 128).to_f64()
No inspira mucha confianza. Pero sigamos adelante analizando la función matmul_python. Es un ejemplo equivalente
a este matmul de numpy que efectúa
la multiplicación de dos matrices bidimensionales y devuelve una tercera. Pero en este ejemplo no se retorna nada,
se pasan las 3 matrices por referencia. ¿Será para evitar allocs de memoria? Al menos si la matriz de resultado
está inicializada a cero python cachea ese objeto y no destruiría el objeto más de 10.000 veces. Pero parece que eso
sucede solo la primera vez, en la segunda vuelta supongo que se come 10.000 ciclos de recolección de los floats no
cacheados de la ejecución anterior. ¿Por qué no ha inicializado las variables en el setup de timeit? De todas formas
si prestamos atención a ese C.rows y C.cols notaremos que no está usando List[List[float]] como tipos de las
matrices pasadas por parámetro, sino Matrix. Si seguimos mirando veremos que éste aparentemente simple test esconde
más trampas que una película de chinos.
Si se hacen cosas raras para mostrar las capacidades de la librería se dice y todo bien. Si se disfraza de benchmark tenemos un despojo de marketing disfrazado de documentación.
Importando el ejemplo a Mojo🔗
De traca. Importa un montón de dependencias de Mojo, luego te dice dejo las 5 líneas de la función matmul_python
intactas y se limita a renombrarlo por matmul_untyped. Muy bien, tienes los santos cojones de decir:
# This exactly the same Python implementation,
# but is infact Mojo code!
def matmul_untyped(C, A, B):
...
y poco después vemos el código para ejecutar el benchmark. El muy sospechoso código del benchmark que ahora es así:
def matrix_getitem(self, i) -> object:
return self.value[i]
def matrix_setitem(self, i, value) -> object:
self.value[i] = value
return None
def matrix_append(self, value) -> object:
self.value.append(value)
return None
def matrix_init(rows: Int, cols: Int) -> object:
value = object([])
return object(
Attr("value", value), Attr("__getitem__", matrix_getitem), Attr("__setitem__", matrix_setitem),
Attr("rows", rows), Attr("cols", cols), Attr("append", matrix_append),
)
def benchmark_matmul_untyped(M: Int, N: Int, K: Int, python_gflops: F64):
C = matrix_init(M, N)
A = matrix_init(M, K)
B = matrix_init(K, N)
for i in range(M):
c_row = object([])
b_row = object([])
a_row = object([])
for j in range(N):
c_row.append(0.0)
b_row.append(random_f64(-5, 5))
a_row.append(random_f64(-5, 5))
C.append(c_row)
B.append(b_row)
A.append(a_row)
@parameter
fn test_fn():
try:
_ = matmul_untyped(C, A, B)
except:
pass
let secs = F64(Benchmark().run[test_fn]()) / 1_000_000_000
let gflops = ((2*M*N*K)/secs) / 1e9
let speedup : F64 = gflops / python_gflops
print(gflops, "GFLOP/s, a", speedup.value, "x speedup over Python")
benchmark_matmul_untyped(128, 128, 128, python_gflops)
0.047082 GFLOP/s, a 8.59x speedup over Python
¿Por qué dice que no ha modificado nada y cambia la implementación de la clase Matrix que es usada dentro del benchmark?
¿Acabas de demostrar un speedup de 8.59x sobre python? No, acabas de demostrar que eres un caradura que miente más que un concejal. Eres un puto despojo. Esta documentación no está hecha para mostrar cosas, está diseñada para ocultarlas. Es tan burdo como un anunció de teletienda.
Añadiendo tipos🔗
¿En qué consiste añadir tipos? Pues otro refactor completito de la parte que ejecuta el benchmark y cambios mínimos en la función testeada. Afortunadamente, no han publicado código en github, por lo que ni los zoquetes contadores de estrellitas picarían con esto. Espero. Eso quiero creer.
Benchmarking shows significant speedups. We increase the size of the matrix to 512 by 512, since Mojo is much faster than Python. benchmark[matmul_naive](512, 512, 512, python_gflops)
1.702316 GFLOP/s, a 310.62x speedup over Python
Adding type annotations gives a huge improvement compared to the original untyped version.
Ahora los tipos son float32, pero el ancho banda se sigue calculando como si siguieran siendo float64. Estoy seguro de que si te pide cambios, acabas con menos dinero del que tenías al principio. !!!Menudo trilero!!! No pierde oportunidad de tratar de meterte un gol. A saber por qué cambió el tamaño de las matrices, seguro que así le cabían también en la caché y nos la cuela otro poquito.
Muy bien, me has demostrado que tienes un 310.62x de habilidad en hacer trampas al solitario.
Vectorizando🔗
Un API portable para generar código vectorizable con instrucciones SIMD suena de miedo. Que más da ya el código, si seguimos aquí es por el cachondeo:
benchmark[matmul_vectorized_1](512, 512, 512, python_gflops)
3.125112 GFLOP/s, a 570.27x speedup over Python
Paralelizando🔗
Más cambios random, que más nos dará. Si te interesa abre el link.
benchmark[matmul_parallelized](512, 512, 512, python_gflops)
11.388119 GFLOP/s, a 2078.00x speedup over Python
Te preguntarás cuántos cores tiene la máquina que ejecuta los tests. No lo se. Ese casi 4x de speedup sobre el ejemplo anterior podrían ser en una máquina de 4 cores o de 64. Se ve que no es relevante, lo importante es ver si llegamos al 35000x de la imagen de presentación.
Tiling🔗
Tiling is an optimization performed for matmul to increase cache locality. The idea is to keep sub-matrices resident in the cache and increase the reuse. The tile function itself can be written in Mojo as:
from Functional import Static2DTileUnitFunc as Tile2DFunc
# Perform 2D tiling on the iteration space defined by end_x and end_y.
fn tile[tiled_fn: Tile2DFunc, tile_x: Int, tile_y: Int](end_x: Int, end_y: Int):
# Note: this assumes that ends are multiples of the tiles.
for y in range(0, end_y, tile_y):
for x in range(0, end_x, tile_x):
tiled_fn[tile_x, tile_y](x, y)
Muy bien hace cosas para mejorar la localidad del caché.
# Use the above tile function to perform tiled matmul.
fn matmul_tiled_parallelized(C: Matrix, A: Matrix, B: Matrix):
@parameter
fn calc_row(m: Int):
@parameter
fn calc_tile[tile_x: Int, tile_y: Int](x: Int, y: Int):
for n in range(y, y + tile_y):
@parameter
fn dot[nelts: Int](k: Int):
C[m,n] += (A.load[nelts](m,k+x) * B.load_tr[nelts](k+x,n)).reduce_add()
vectorize[nelts, dot](tile_x)
# We hardcode the tile factor to be 4.
alias tile_size = 4
tile[calc_tile, nelts * tile_size, nelts * tile_size](C.cols, A.cols)
parallelize[calc_row](C.rows)
El lector ávido y atento ya habrá dejado de perder el tiempo con este despojo de marketing hace rato. Pero el lector
menos técnico, el que prefiere leer comentario y texto a código habrá notado el hardcoding del tile_size.
¿Por qué no ocultan esta triquiñuela que no parece muy portable?
benchmark[matmul_tiled_unrolled_parallelized](512, 512, 512, python_gflops)
12.243320 GFLOP/s, a 2234.05x speedup over Python
¿Será porque siguen consiguiendo mejoras y les da igual?
Buscando el valor para el tile_factor🔗
No, se reservan el último conejo a sacar de la chistera. Una especie de profiling guided compilation a la que llaman
autotune y ajusta los valores en función de tu hardware.
¿Cuánto tarda este proceso en ejecutarse? ¿Se cachea la compilación para evitar overhead en runtime? Que más da. Eso no es relevante, lo relevante es esto:
benchmark[matmul_autotune](512, 512, 512, python_gflops)
22.824017 GFLOP/s, a 4164.72x speedup over Python
Lo relevante es calar la idea fuerza de que el lenguaje mojo despojo le patea el culito a cualquier otro lenguaje.
Conclusiones finales🔗
¿Qué pasaría si este artículo hubiera sido escrito por una persona técnica y honesta?
Seguramente podríamos deleitarnos con su lectura y soñar con que este proyecto avance y llegue a buen puerto.
Por ahora me centraría en opciones del mundo real como las propuestas en el libro Algorithms for Modern Hardware. Muy interesante para entender los ejemplos de mojo despojo y entender por qué detrás del humo hay un problema que necesita ser solucionado con avances en la tecnología.